Having been in the game of supply chain analytics for so long, we’ve noticed that data is the single biggest challenge our customers and consultants encounter. Supply chain data is distributed in myriad enterprise and external databases, access to the data is limited, it’s in many different formats and structures, it’s missing important pieces and it’s in huge volumes. As much as 80 percent of any analysis project can be spent dealing with data issues, and that costs valuable time and places key decisions at risk because of delayed response.
We have worked with our own consultants and customers to develop tools and processes to address the five key data processes that are required to successfully navigate data processing issues in order to make supply chain optimization a sustainable business process:
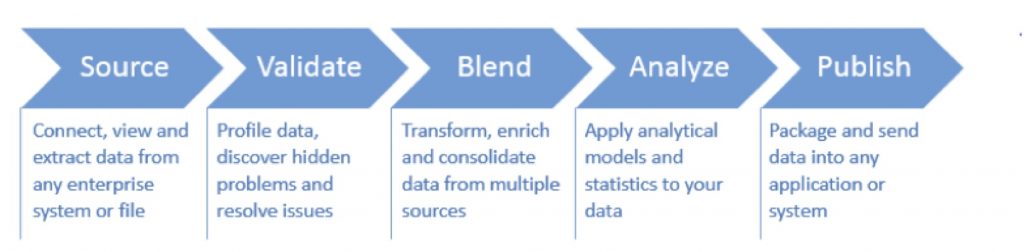
Five Steps of Data Processing
With the right approach, data challenges can become an issue of the past. Here is a summary of these five key data processing steps to help streamline and automate supply chain data analysis.
- Source
Pre-configured and adaptable data connectors can enable your business users to easily tap into nearly any data system. This means you can easily visualize the data within source systems regardless of the database size or location, without the need to replicate the data on your local computer.
- Validate
With the huge volumes of data today, it’s time-consuming and nearly impossible to quickly evaluate your data to identify patterns and potential problems to ensure consistency. Data profiling can be used to identify data significance and patterns, visualize groupings, and locate potential challenges such as missing fields, improper formats, or multiple naming conventions for like items.
- Blend
Next you’ll need to blend your data by changing formats, adjusting structures, joining columns or unpivoting tables. You may also need to bring in additional data from personal files or third-party sources to supplement the enterprise data in your workspace. In this case, you should create rules to automate the process of merging new information and blending it with existing information.
- Analyze
Graphs can help you visualize your data in a different way, but can only create surface-level insight. Statistical classification and prediction models can quickly deliver meaningful insight that might otherwise remain hidden or unobtainable. Descriptive analytics allows users to convert larger datasets into condensed, meaningful, and more useful information that is suitable for human consumption.
- Publish
Now you’re ready to run all of the data actions, macros, and workflows to move data from the original source data systems and formats through the entire blending process and into a fresh unified data file that is ready to be sent to reporting applications, supply chain modeling environments, or new databases. You may want to publish output directly to local or network databases. Create new tables, append values to existing tables, or update existing table values.
Modern supply chains require a continuous optimization process that is driven by the most current data. New technologies and advances in big data management mean that your business users can now connect directly to the systems that run the enterprise and build repeatable data transformation workflows. That makes it possible to harness all of the supply chain data your systems are generating for real business insight and quicker time-to-answer for tough supply chain questions.
 Bennett Wilkins, Director of Product Management, LLamasoft. He is the director of product management for LLamasoft® Data Guru® and has been instrumental in developing this market-driven solution over the past four years, drawing from his experience as a consultant and data analyst. Previously, Bennett served as a product engineering manager and a solutions manager, where he focused on data process automation and sustainable business process development for numerous Fortune 500 customers.
Bennett Wilkins, Director of Product Management, LLamasoft. He is the director of product management for LLamasoft® Data Guru® and has been instrumental in developing this market-driven solution over the past four years, drawing from his experience as a consultant and data analyst. Previously, Bennett served as a product engineering manager and a solutions manager, where he focused on data process automation and sustainable business process development for numerous Fortune 500 customers.

Five Steps to Navigating Supply Chain Analytics Data Challenges
Having been in the game of supply chain analytics for so long, we’ve noticed that data is the single biggest challenge our customers and consultants encounter. Supply chain data is distributed in myriad enterprise and external databases, access to the data is limited, it’s in many different formats and structures, it’s missing important pieces and it’s in huge volumes. As much as 80 percent of any analysis project can be spent dealing with data issues, and that costs valuable time and places key decisions at risk because of delayed response.
We have worked with our own consultants and customers to develop tools and processes to address the five key data processes that are required to successfully navigate data processing issues in order to make supply chain optimization a sustainable business process:
Five Steps of Data Processing
With the right approach, data challenges can become an issue of the past. Here is a summary of these five key data processing steps to help streamline and automate supply chain data analysis.
Pre-configured and adaptable data connectors can enable your business users to easily tap into nearly any data system. This means you can easily visualize the data within source systems regardless of the database size or location, without the need to replicate the data on your local computer.
With the huge volumes of data today, it’s time-consuming and nearly impossible to quickly evaluate your data to identify patterns and potential problems to ensure consistency. Data profiling can be used to identify data significance and patterns, visualize groupings, and locate potential challenges such as missing fields, improper formats, or multiple naming conventions for like items.
Next you’ll need to blend your data by changing formats, adjusting structures, joining columns or unpivoting tables. You may also need to bring in additional data from personal files or third-party sources to supplement the enterprise data in your workspace. In this case, you should create rules to automate the process of merging new information and blending it with existing information.
Graphs can help you visualize your data in a different way, but can only create surface-level insight. Statistical classification and prediction models can quickly deliver meaningful insight that might otherwise remain hidden or unobtainable. Descriptive analytics allows users to convert larger datasets into condensed, meaningful, and more useful information that is suitable for human consumption.
Now you’re ready to run all of the data actions, macros, and workflows to move data from the original source data systems and formats through the entire blending process and into a fresh unified data file that is ready to be sent to reporting applications, supply chain modeling environments, or new databases. You may want to publish output directly to local or network databases. Create new tables, append values to existing tables, or update existing table values.
Modern supply chains require a continuous optimization process that is driven by the most current data. New technologies and advances in big data management mean that your business users can now connect directly to the systems that run the enterprise and build repeatable data transformation workflows. That makes it possible to harness all of the supply chain data your systems are generating for real business insight and quicker time-to-answer for tough supply chain questions.
TAGS
Subscribe to Our YouTube Channel
TOPICS
Categories
Subscribe to Our Podcast
TRENDING POSTS
Sponsors